
Agentplex Weekly - Issue #5
Building Reliable Agents. Llama-3+ LangChain Agent Recipes. Cohere Agents Cookbooks. Scalable Self-Reflective Agents. Buffer of Thoughts. Chain of Agents.

On building reliable [enterprise] agents. The level of interest and pent-up demand in enterprise AI agents is absolutely astonishing. According to McKinsey & Co consultancy, enterprise GenAI agents “could yield $2.6 trillion to $4.4 trillion annually in value across more than 60 enterprise use cases.” Read more here: The promise and the reality of AI agents in the enterprise.
If you are a small startup or an independent developer building AI agents for enterprise, this could be a huge opportunity for you.
Early days but… Yes, it’s still early days, as there are quite a few challenges that need to be solved in terms of reliability, accuracy, performance, and scalability of LLM-based agents. We believe these issues will be fixed sooner that most expect. We are quickly moving from a phase of “research & experimentation” to a phase of “early adoption” in enterprise. Our advice is that you invest time in making sure your agent is not just intelligent, but reliable too. Let me share two great posts on that:
Lessons learned from building agents for automating workflows. A brilliant post by Miguel CTO at Parcha, a startup specialised in automating ops processes in fintech and banks. Miguel writes about the risks and challenges of solely relying on autonomous agentic behaviour for complex workflows, the importance of agents on rails, domain focus, and recommendations on using a structured agent workflow approach. An awesome read on the lessons learned when automating workflows with LLM-based agents. Blogpost: Agents aren’t all you need.

Building reliable agents. In this interview, Cai CTO at Ironclad - a pioneer startup in agents for the legal sector- shares great insights and advice on building agents for enterprise clients. Cai discusses his experience from the trenches on building agents for the legal sector, imo one of the toughests. He talks about the RAG and ReAct patterns in the real-world, the benefits of visual programming for developing agents, open source AI, the future of agents, and much more. Blogpost and video: How to build reliable AI agents.

A Collection of Recipes & Cookbooks
Build & run open source Llama-3 agents locally, reliably. A nice post with 3 recipes from Meta AI + LangChain on how to build oss agents that run in your local environment reliably. 1) LangGraph tool-calling agents, using Groq for super fast inference and tool-calling, 2) RAG agents using LangGraph and Groq for complex self-corrective control flow, and 3) Take the RAG agent and make it run locally using the new, fast, fully open source, Nomic embeddings and Ollama. Checkout the blogpost and video explainer at the bottom: LangChain <> Llama3 Cookbooks.

Hallucination guardrails with GPT-4o. A guardrail is a set of rules and checks designed to ensure that the outputs of an LLM are accurate, appropriate, and aligned with user expectations. In this notebook, Roy walks through the process of developing an output guardrail that specifically checks model outputs for hallucinations. Blogpost and iPynb repo: Developing Hallucination Guardrails.
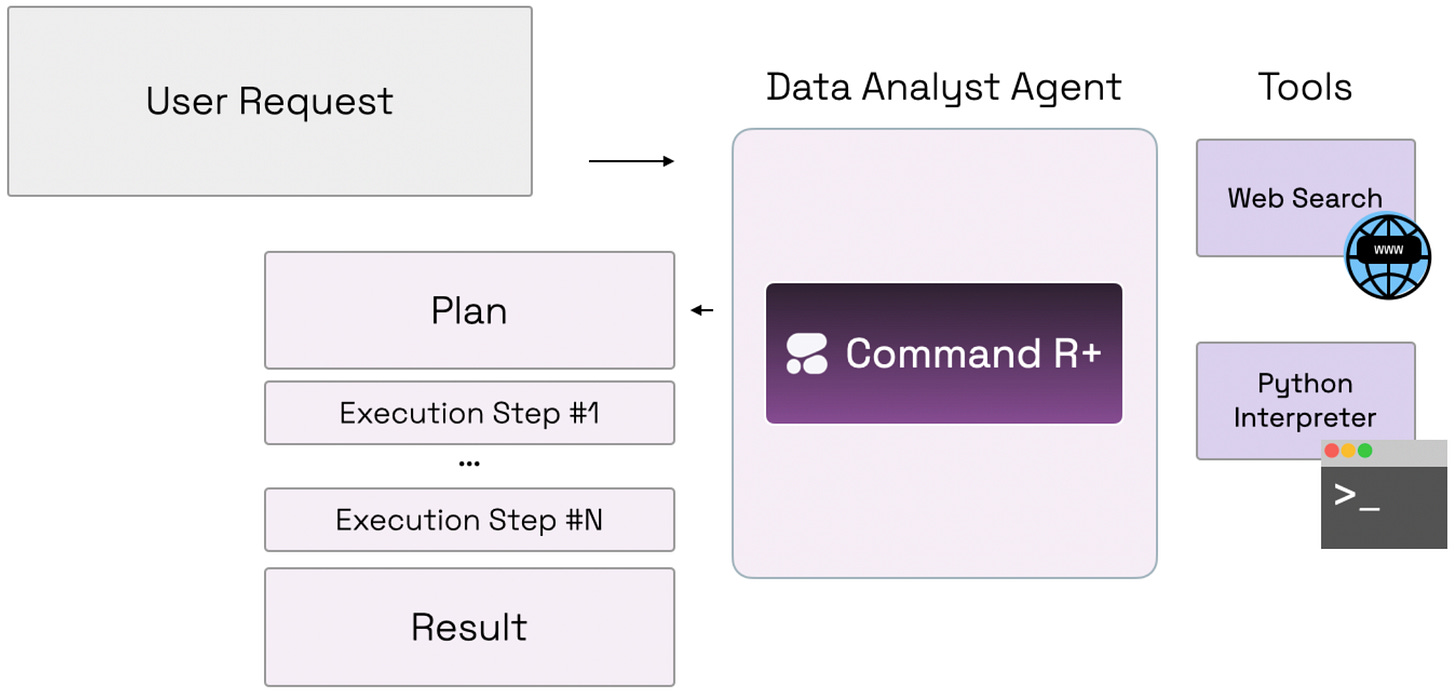
The Cohere Agents Cookbook. A collection of 10 iPynbs on how to build powerful agents with Cohere API + Command R+, and tools to connect to external services, like search engines, APIs, and DBs. The agents can be used to automate tasks, analyse data, search, query answering, and more. Link: Cohere Agents Cookbook.


Three interesting research papers
AnyTool: Self-reflective agents at scale. This paper starts with an assumption: An agent that uses a vast number of API calls should be able to resolve diverse user queries very accurately. The researchers then set out to build a proficient agent that uses GPT-4 function calling and +16K APIs from Rapid API. AnyTool implements a hierarchical API retriever, a query solver, and self-reflection pattern. The researches claim that AnyTool beats ToolLLM by +35.4%. Checkout the paper & repo here: AnyTool: Self-Reflective, Hierarchical Agents for Large-Scale API Calls.

Buffer of Thoughts. Two days ago, researchers at UC Berkley introduced a novel and versatile thought-augmented reasoning approach designed to enhance the accuracy, efficiency, and robustness of LLMs. This new approach is based on storing high-level thought-templates in a meta-buffer that can be adaptively instantiated for different reasoning tasks. Checkout the paper & repo: Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models.


Chain-of-Agents. This week, Google AI etal. researchers just introduced Chain-of-Agents, a training free, task agnostic, and highly-interpretable framework that harnesses multi-agent collaboration for long-context tasks. It consists of multiple worker agents who sequentially communicate to handle different segmented portions of the text, followed by a manager agent who synthesizes these contributions into a coherent final output. Paper: Chain of Agents: LLMs Collaborating on Long-Context Tasks.

Update on the Agentplex AI Agents Global Challenge
We just hit 400 applications!
Reminder: We plan to extend the submission deadline beyond the original date on 1 September. So you can still keep refining your application up to the final submission deadline to be announced in July.
Next month, we’ll announce important further details, including a better allocation of the $1M prize pool, more benefits for the participants, and some guidelines and ideas.
To receive updates and further announcements, keep reading this newsletter, join our Discord channel, follow us on Agentplex X channel, or simply drop us an email.
Upcoming AI Agents hackathons and meetups, July
Next month, we’re planning to organise a meetup and a hackathon in London. If you are interested in giving a talk or do a demo at a meetup or suggesting ideas for a hackathon, please contact Carlos here.
If you are interested in a summer internship, please submit an email here to apply.
Thank you for reading Agentplex newsletter. Have a great day.